Bayesian Machine Learning
Bayesian Machine Learning
These is a review of Bayesian Machine Learning. It’s based on HSE’s course on this topic.
Maximum Likelihood Estimation (MLE)
The ML estimate for \(\theta\) is the value under which the data are most likely, i.e.
\[\boxed{\hat{\theta}_{ML} \in \text{argmax}_\theta p(y|\theta)}\]Example: We know that a fair coin has \(p(\text{head}) = p(\text{tail}) = 1/2\). Now imagine you have a coin and you don’t know if it is fair or not. You decide to throw the coin \(m\) times, where you observe \(m_H\) times head, and \(m_T\) times tail, where \(m_H + m_T = m\). Now you ask given this observation, what is the probability of \(p(\text{head}), p(\text{tail})\) for this coin? We know that if \(p(\text{head}) =\theta\), then the likelihood of such observation is
\[p(y|\theta) = \theta^{m_H} (1-\theta)^{m-m_H}\]Now, we are interested to find a \(\hat \theta_{ML}\) such that the above probability is maximized. Instead of the probability, we maximize its logarithm which will be easier. We have
\[l(\theta) = m_H \log(\theta) + (m-m_H) \log(1-\theta)\]finding the \(\text{argmax}_\theta\) for the above equation we have
\[\frac{d}{d\theta}d(\theta)|_{\hat\theta} = 0 = \frac{m_H}{\theta}|_{\hat\theta} - \frac{m-m_H}{1-\theta}|_{\hat\theta}\] \[\longrightarrow \hat{\theta} = \frac{m_H}{m}\]Maximum a posteriori (MAP) estimation
We learned that in MLE estimation we find \(\theta\) to maximize the likelihood function \(p(y\mid \theta)\). Now, in MAP, we find \(\theta\) such that the posterior \(p(\theta\mid y)\) is maximized, i.e.,
\[\boxed{\hat{\theta}_{MAP} \in \text{argmax}_\theta p(\theta\mid y) = \text{argmax}_\theta \frac{p(y\mid \theta) p(\theta)}{p(y)}}\]Since the denominator does not depend on \(\theta\), we have
\[\hat{\theta}_{MAP} = \text{argmax}_\theta p(y\mid \theta)p(\theta) = \text{argmax}_\theta \log p(y\mid \theta) + \log p(\theta)\]The last term, \(\log p(\theta)\) is known as our prior belief.
Example: Again, imagine the same coin flip problem. Imagine we take the prior to be a beta distribution as
\[p(\theta) = \beta(\theta;\alpha,\beta) = A~ \theta^\alpha (1-\theta)^{\beta}\]where \(A\) is a constant to make \(\int p(\theta)\text{d}\theta=1\). Now finding the solution to the MAP estimator, we find that
\[\hat{\theta}_{MAP} = \text{argmax}_\theta \log p(y\mid \theta) + \log p(\theta)\] \[\frac{m_H}{\theta}\mid _{\hat\theta} - \frac{m-m_H}{1-\theta}\mid _{\hat\theta} + \frac{\alpha}{\theta}\mid _{\hat\theta} - \frac{\beta}{1-\theta}\mid _{\hat\theta} = 0\] \[\hat{\theta}_{MAP} = \frac{m_H + \alpha}{m+\alpha+\beta }\]The point of \(\alpha, \beta\) coming from the prior in the above equation will be a regularizer. Imagine, we only throw the coin only once, then the ML gives \(\hat{\theta}_{ML}=1\), however, \(\hat{\theta}_{MAP} = \alpha/(\alpha+\beta)\).
Point estimation and probabilistic linear regression
Imagine we are given $m$ datapoints, \((x_1,y_1), \cdots, (x_m,y_m)\), where \(x_i\)’s are independent variables and \(y_i\)’s are dependent. Assuming a linear relationship as
\[y_i \sim \theta^\top x_i + \epsilon\]where \(\epsilon \sim \mathcal{N}(0,\sigma^2)\). Assuming the independence between the \(y_i\)’s, we can write
\[p(y\mid x,\theta)= \Pi_{i=1}^m p(y_i\mid x_i,\theta) = \Pi_{i=1}^m \mathcal{N}(y_i;\theta^\top x_i,\sigma^2)\]Finding the maximum of log-likelihood, we obtain
\[\hat{\theta}_{ML} = \text{argmax}_\theta p(y\mid x,\theta) = \text{argmin}_\theta \sum_{i=1}^m (y_i - \theta^\top x_i)^2\]which is the equivalent to ordinary least squares.
Now, trying the MAP estimate, we first need to assume a prior for the \(\theta\) variables. As an initial estimate we assume \(\theta \sim \mathcal{N}(0, \nu^2\mathbf{I})\). Finding the MAP solution we find that
\[\hat{\theta}_{MAP} = \text{argmax}_\theta \log p(y\mid \theta) + \log p(\theta)\] \[\hat{\theta}_{MAP} = \text{argmin}_\theta \sum_{i=1}^m (y_i-\theta^\top x_i)^2 + \frac{\sigma^2}{\nu^2} \mid \mid \theta\mid \mid ^2\]which is the same as ML solution with a regularization term.
Conjugate priors
We often would like to find the full posterior, \(p(\theta\mid y)\). If we know the full posterior distribution, then we can do posterior predictive distribution as
\[p(y_{m+1}\mid y) = \int p(y_{m+1}\mid y,\theta)~p(\theta\mid y) d\theta = \int p(y_{m+1}\mid \theta)~p(\theta\mid y) d\theta\]The second part is because \(y_{m+1}\) and \(y\) are conditionally independent. If we would like to find the full posterior, then
\[p(\theta\mid y) = \frac{p(y\mid \theta)p(\theta)}{p(y)}\]The bottom part is just a normalizer. So we need to choose the prior, \(p(\theta)\), such that with the likelihood distribution, \(p(y\mid \theta)\), we are able to track the distribution. Selecting prior in such a way that the \(p(y\mid \theta)p(\theta)\) becomes tractable is known as a selection of conjugate priors for \(p(y\mid \theta)\).
Exponential families and conjugate priors
The family of distribution \(\mathcal{F}\) is called exponential family if every member of \(\mathcal{F}\) has the form
\[\boxed{p(y_i\mid \theta) = f(y) g(\theta)\exp(\phi(\theta)^\top u(y_i))}\]where $f(\cdot), g(\cdot), \phi(\cdot),u(\cdot)$ are some functions. For example, an exponential distribution is an exponential family distribution:
\[p(y\mid \theta) = \theta e^{-\theta y}\]or a beta distribution:
\[p(y\mid \theta) = \theta^{y} (1-\theta)^{1-y} = \exp(y\log\theta + (1-y)\log(1-\theta)) = (1-\theta)\log(y \log\frac{\theta}{1-\theta})\]Normal distribution is also an exponential family.
If the \(p(y_i\mid \theta)\) is coming from an exponential family distribution, then if \(y_i\)’s are independent, the likelihood becomes
\[p(y\mid \theta) = \Pi_{i=1}^m p(y_i\mid \theta) = \left[\Pi_{i=1}^m f(y_i)\right] g(\theta)^m \exp\left( \phi(\theta)^\top \sum_{i=1}^m u(y_i)\right)\]Now, we can select the prior as
\[p(\theta) \sim g(\theta)^\eta \exp(\phi(\theta)^\top \nu)\]where \(\eta,\nu\) are hyper-parameters.
Now you might ask, doesn’t the choice of prior doesn’t matter? Can we really pick any prior distribution? In the next part, we show that as long as you pick a prior that assigns non-zero probabilities to every possible value of $\theta$, the solution of MAP converges to the true solution $\theta^$, or more precisely, $\theta^$ corresponds to the likelihood model which is closest to the true generating distribution. The closeness of the distributions is defined using KL divergence.
KL divergence
The KL divergence between two distributions \(p\) and \(q\) is defined as
\[\boxed{D_{KL}(p\mid \mid q) := \int_x p(x) \log \frac{p(x)}{q(x)}dx}\\ \to D_{KL}(p\mid \mid q)= \mathbf{E}_p[\log p(x) - \log q(x)]\]Note that \(D_{KL}(p\mid \mid q)\) is always positive since
\[-D_{KL}(p\mid \mid q) = \int p(x)\left(-\log \frac{p(x)}{q(x)}\right) dx \leq -\log \int p(x) \frac{q(x)}{p(x)} dx =0\] \[\rightarrow D_{KL}(p\mid \mid q)\geq 0\]and the equality with zero only happens when \(p=q\). Now, we want to use the KL divergence to find the distribution from the likelihood family that is closest to the true generating function
\[\theta^* = \text{argmin}_\theta D(q(\cdot) \mid \mid p(\cdot\mid \theta))\]Imagine we have \(y=(y_1,\cdots, y_m)\) as a set of independent samples from an arbitrary distribution \(q(y)\). We assume a family \(\mathcal{F}\) of likelihood distributions with \(\Theta = \{ \theta: p(\cdot \mid \theta) \in \mathcal{F}\}\) the finite parameter space. Our goal is to show that if \(p(\theta=\theta^*)>0\), then \(p(\theta=\theta^*\mid y)\to1\) as the number of observation increases or \(m\to\infty\). Consider \(\theta\neq \theta^*\), then
\[\log \frac{p(\theta\mid y)}{p(\theta^*\mid y)} = \log \frac{p(y\mid \theta) p (\theta)}{p(y\mid \theta^*) p (\theta^*)} = \log \frac{p (\theta)}{p (\theta^*)} + \sum_{i=1}^m \log \frac{p(y_i\mid \theta) }{p(y_i\mid \theta^*)}\]where we used the fact that \(p(\theta^*) \neq 0\). We have
\[\frac{1}{m} \sum_{i=1}^m \log \frac{p(y_i\mid \theta) }{p(y_i\mid \theta^*)} \to \mathbf{E}_q\left[ \log \frac{p(y_i\mid \theta) }{p(y_i\mid \theta^*)}\right]\]Expanding the Expected value we have
\[\mathbf{E}_q\left[ \log \frac{p(y_i\mid \theta) }{p(y_i\mid \theta^*)}\right] = \mathbf{E}_q\left[ \log \frac{p(y_i\mid \theta) }{p(y_i\mid \theta^*)}\frac{q(y)}{q(y)}\right] = \mathbf{E}_q\left[ \log \frac{q(y) }{p(y_i\mid \theta^*)}- \log \frac{q(y)}{p(y_i\mid \theta)} \right]\] \[\mathbf{E}_q\left[ \log \frac{p(y_i\mid \theta) }{p(y_i\mid \theta^*)}\right] = D_{KL}\left(q(\cdot) \mid \mid p(\cdot\mid \theta^*)\right) - D_{KL}\left(q(\cdot) \mid \mid p(\cdot\mid \theta)\right) < 0\]The above result is negative since we assume that \(\theta^*\) minimizes the KL divergence between \(q(\cdot)\) and \(p(\cdot\mid \theta)\). So far we have found that
\[\sum_{i=1}^m \log \frac{p(y_i\mid \theta) }{p(y_i\mid \theta^)} \to m\mathbf{E}_q\left[ \log \frac{p(y_i\mid \theta) }{p(y_i\mid \theta^)}\right] \to -\infty\]since the expected value we found to be negative, and as \(m\to\infty\), the value goes to negative infinity. Plugging back into the initial equation we have
\[\log \frac{p(\theta\mid y)}{p(\theta^*\mid y)} = \log \frac{p (\theta)}{p (\theta^*)} + \sum_{i=1}^m \log \frac{p(y_i\mid \theta) }{p(y_i\mid \theta^*)} = \log \frac{p (\theta)}{p (\theta^*)} -\infty \to -\infty\] \[\log \frac{p(\theta\mid y)}{p(\theta^*\mid y)} \to -\infty\]This implies that \(p(\theta\mid y)/p(\theta^*\mid y) \to 0\), which means that \(p(\theta\mid y) \to 0\). We started with the fact that \(\theta\neq\theta^*\). So if \(p(\theta\mid y)\to 0\) for \(\theta\neq\theta^*\), then \(p(\theta^*\mid y)\to 1\).
Expectation Maximization
Guassian Mixture Models:
In Gaussian Mixture model, you assume that your data is coming from a combination of Gaussian (Gaussian Mixture). There is a latent variable, \(z\), that determines which Gaussian to pick or how to combine the Gaussian models. In this latent model, we are interested to find \(\theta\) parameters of the Gaussian, such that \(p(x\mid \theta)\) is maximized. Let’s assume that the latent variable is discrete and \(z=1\) or \(2\). The probability of observing a datapoint is
\[p(x\mid \theta) = \sum_{c=1}^2 p(x,z=c\mid \theta) = \sum_{c=1}^2 p(z=c)~p(x\mid \theta,z)\]Our goal as usual is to find \(\max_\theta p(X\mid \theta))\). We have
\[\max_\theta p(X\mid \theta) = \max_\theta \log p(X\mid \theta)= \max_\theta \log \Pi_{i=1}^N p(x_i\mid \theta)= \max_\theta \sum_{i=1}^N \log p(x_i\mid \theta)\] \[\begin{align*} \max_{\theta} p(X\mid \theta) &= \max_{\theta} \sum_{i=1}^N \log \sum_{c=1}^2 p(x_i,z_i=c\mid \theta) \\ &= \max_{\theta} \sum_{i=1}^N \log \sum_{c=1}^2 \frac{q(z_i=c)}{q(z_i=c)}p(x_i,z_i=c\mid \theta) \\ &=\max_{\theta} \sum_{i=1}^N \log \sum_{c=1}^2q(z_i=c) \frac{p(x_i,z_i=c\mid \theta)}{q(z_i=c)}) \\ &\geq \max_{\theta} \sum_{i=1}^N \sum_{c=1}^2 q(z_i=c) \log \frac{p(x_i,z_i=c\mid \theta)}{q(z_i=c)}) \end{align*}\]So, in summary we have found the following
\[\boxed{\log p(X\mid \theta) \geq \mathcal{L}(\theta,q) \text{ for any } q }\] \[\boxed{\mathcal{L}(\theta,q) = \sum_{i=1}^N \sum_{c=1}^2 q(z_i=c) \log \frac{p(x_i,z_i=c\mid \theta)}{q(z_i=c)}) }\]So, we do the above part in two steps as follows (Expectation step)
\[\boxed{q^{k+1} = \text{argmax}_q \mathcal{L}(\theta^k,q)}\]and next (Maximization step)
\[\boxed{\theta^{k+1} = \text{argmax}_\theta \mathcal{L}(\theta,q^{k+1})}\]E-Step:
Let’s look at the E-Step. In order to do so, let’s look at the difference between the log-likelihood and the lowerbound that we defined
\[\begin{align*} \log p(X,\theta)-\mathcal{L}(\theta,q) &= \sum_{i=1}^N \log p(x_i\mid \theta) - \sum_{i=1}^N \sum_{c=1}^2 q(z_i=c) \log \frac{p(x_i,z_i=c\mid \theta)}{q(z_i=c)} \\ &= \sum_{i=1}^N \log p(x_i\mid \theta) \sum_{c=1}^2 q(z_i=c) - \sum_{i=1}^N \sum_{c=1}^2 q(z_i=c) \log \frac{p(x_i,z_i=c\mid \theta)}{q(z_i=c)} \\ &= \sum_{i=1}^N \sum_{c=1}^2 q(z_i=c) \left( \log p(x_i\mid \theta) -\log \frac{p(x_i,z_i=c\mid \theta)}{q(z_i=c)} \right)\\ &= \sum_{i=1}^N \sum_{c=1}^2 q(z_i=c) \left( \log \frac{q(z_i=c) p(x_i\mid \theta) }{p(x_i,z_i=c\mid \theta)} \right) \\ &= \sum_{i=1}^N \sum_{c=1}^2 q(z_i=c) \left( \log \frac{q(z_i=c) }{p(z_i=c\mid x_i,\theta)} \right) \\ &= D_{KL}\left(q(z_i=c) \mid \mid p(z_i=c\mid x_i,\theta) \right) \end{align*}\]So we found that
\[\boxed{\log p(X\mid \theta) - \mathcal{L}(\theta,q) = D_{KL}\left({q(z_i=c) }\mid \mid {p(z_i=c\mid x_i,\theta)} \right)}\]which basically means that to maximize lowerbound \(\mathcal{L}(\theta,q)\) (which minimizes the distance between the log-likelihood and the lowerbound), we need to minimize the KL-divergence on the righthandside. The KL divergence is zero when the two PDFs are the same, so
\[q(z_i=c) = p(z_i=c\mid x_i,\theta)\]M-Step:
Now we are interested to maximize the following with respect to \(\theta\) as
\[\begin{align*} \mathcal{L}(\theta,q) &= \sum_{i=1}^N \sum_{c=1}^2 q(z_i=c) \log \frac{p(x_i,z_i=c\mid \theta)}{q(z_i=c)} \\ &= \sum_{i=1}^N \sum_{c=1}^2 q(z_i=c) \log {p(x_i,z_i=c\mid \theta)} - \sum_{i=1}^N \sum_{c=1}^2 q(z_i=c) \log {q(z_i=c)} \\ &= \mathbf{E}_q \log p(X,Z\mid \theta) \end{align*}\]Summary of Expectation-Maximization:
E-step:
\[\boxed{q^{k+1}(z_i) = p(z_i\mid x_i,\theta^k) }\]which results in the fact that \(\log p(X,\theta) = \mathcal{L}(\theta,q^{k+1})\). Next for the M-step, we have
\[\boxed{\theta^{k+1} = \text{argmax}_\theta \mathbf{E}_q \log p(X,Z\mid \theta)}\]Note that this maximizes the lower bound, however it is guaranteed that \(\log p(X\mid \theta^{k+1}) \geq \mathcal{L}(\theta^{k+1},q^{k+1})\)
Convergence
We have
\[\log p(X\mid \theta^{k+1}) \geq \mathcal{L}(\theta^{k+1},q^{k+1}) \geq \mathcal{L}(\theta^k,q^{k+1}) = \log p(X\mid \theta^k)\]Gaussian Mixture Models (GMM)
In these models, we assume that the data is coming from a mixture of Gaussian distributions \(\mathcal{N}(\mu,\Sigma)\) and the latent distribution is a categorical distribution \(\phi\). This basically means that
\[\boxed{p(X) = \sum_{k=1}^K \pi_k \mathcal{N}(X\mid \mu_k,\Sigma_k)}\]where \(\sum_k \pi_k = 1\). Note that \(\theta = \{ \mu_1,\Sigma_1, \cdots, \mu_K,\Sigma_K\}.\) Now, let’s assume the latent variable is called \(z_i\). Using Expectation-Maximization that we discussed here, we find that
\[q(z_i = k) = p(z_i=k\mid x_i,\theta) = \frac{p(z_i=k) p(x_i \mid z_i=k,\theta) }{p(x_i\mid \theta)} = \frac{p(z_i=k)p(x_i \mid z_i=k,\theta) }{\sum_{k} p(z_i=k) p(x_i \mid z_i=k,\theta) }\] \[\boxed{q(z_i=k) = \frac{\pi_k \mathcal{N}(x_i\mid \mu_k,\Sigma_k)}{\sum_k\pi_k \mathcal{N}(x_i\mid \mu_k,\Sigma_k)}}\]Next, in the Maximization step, we have
\[\theta^*= \max_\theta \mathbf{E}_q \log p(X,Z\mid \theta) = \max_\theta \log p(X\mid \theta) \\ \theta^* = \max_\theta \sum_i \log \left( \sum_k \pi_k \mathcal{N}(x_i\mid \mu_k,\sigma_k) \right)\]Taking the derivative with respect to the \(\mu_k\), we find that
\[\frac{\partial \cdots}{\partial \mu_k} = 0 = \sum_i \frac{\pi_k \mathcal{N}(x_i\mid \mu_k,\sigma_k)}{\sum_k \pi_k \mathcal{N}(x_i\mid \mu_k,\sigma_k) } \\ \sum_i q(z_i=k) \Sigma_k^{-1}(x_i - \mu_k) =0 = \sum_i q(z_i=k) (x_i - \mu_k)\] \[\boxed{\mu_k =\frac{\sum_i q(z_i=k) x_i}{\sum_i q(z_i=k)}}\]Similarly, we can find that
\[\boxed{\Sigma_k = \frac{ \sum_i q(z_i=k)(x_i-\mu)^\top(x_i-\mu)}{ \sum_i q(z_i=k)} }\]K-Means as EM
Imagine the K-means model, where we randomly initialize \(\theta = \{\mu_1, \cdots, \mu_C\}\) points, and then we repeat the following steps until convergence
- For each point we calculate the closest centroid
- Update centroid
The above K-means model can be think of as a GMM. Imagine we fix the covariance matrix to be identity, $\Sigma_k = I$, and also we fix the weights to be \(\pi_k = 1/\#\text{of Gaussians}\). We then will have
\[p(x_i\mid z_i=k,\theta) = \frac{1}{Z} \exp\left(-\frac{1}{2} \\mid x_i-\mu_k\\mid ^2\right)\]Then, in the E-step, we pick \(q(z)\) such that they belong to the delta functions. Then are interested to find a function from the family of delta functions such that
\[q(z_i) = \begin{cases} 1 & \text{ if } z_i = \text{argmax}_k p(z_i=k\mid x_i,\theta)\\ 0 & \text{otherwise}\end{cases}\]Note that
\[p(z_i=k\mid x_i,\theta) = \frac{1}{Z} p(x_i\mid z_i,\theta) p(z_i\mid \theta) = \frac{1}{Z} \exp(-\frac{1}{2}\\mid x_i-\mu_k\\mid ^2) \pi_k\]So the above maximization problem becomes
\[q(z_i) = \begin{cases} 1 & \text{ if } z_i = \text{argmin}_k \\mid x_i-\mu_k\\mid ^2 \\ 0& \text{otherwise}\end{cases}\]which is the same as the first step in the K-means. Now, lets look at the M-step, using the GMM derivation that we did above, we ha
\[\mu_k =\frac{\sum_i q(z_i=k) x_i}{\sum_i q(z_i=k)} = \frac{\sum_{i:z_i=k} x_i}{\sum_{i:z_i=k} 1}\]Implementing GMM in python
So in GMM we are implementing the following formulae
E-step:
\[q(z_i=k) = \frac{\pi_k \mathcal{N}(x_i\mid \mu_k,\Sigma_k)}{\sum_k\pi_k \mathcal{N}(x_i\mid \mu_k,\Sigma_k)}\]M-Step:
\[\mu_k =\frac{\sum_i q(z_i=k) x_i}{\sum_i q(z_i=k)}\] \[\Sigma_k = \frac{ \sum_i q(z_i=k)(x_i-\mu)^\top(x_i-\mu)}{ \sum_i q(z_i=k)}\]from scipy import stats
# here we denote q(z_i=k) with a NxC matrix called gamma
# where N is the number of poitns i=1,...,N
# and C is the number of clusters
def E_step(X, pi, mu, sigma):
"""
Performs E-step on GMM model
Each input is numpy array:
X: (N x d), data points
pi: (C), mixture component weights
mu: (C x d), mixture component means
sigma: (C x d x d), mixture component covariance matrices
Returns:
gamma: (N x C), probabilities of clusters for objects
P(z\mid x) = (p(x\mid z) p(z))/(sum_z p(x\mid z) p(z) )
gamma =
"""
N = X.shape[0] # number of objects
C = pi.shape[0] # number of clusters
d = mu.shape[1] # dimension of each object
gamma = np.zeros((N, C)) # distribution q(T)
for i in range(C):
pi_i = pi[i]
gamma[:,i] = pi_i*stats.multivariate_normal(mu[i,:],sigma[i,:,:]).pdf(X)
gamma = gamma/np.sum(gamma,axis=1).reshape(-1,1)
return gamma
def M_step(X, gamma):
"""
Performs M-step on GMM model
Each input is numpy array:
X: (N x d), data points
gamma: (N x C), distribution q(T)
Returns:
pi: (C)
mu: (C x d)
sigma: (C x d x d)
"""
N = X.shape[0] # number of objects
C = gamma.shape[1] # number of clusters
d = X.shape[1] # dimension of each object
resp_weights = np.sum(gamma,axis=0)
pi = resp_weights/(1.0*N)
mu = np.dot(gamma.T,X)/resp_weights.reshape(-1,1)
sigma = np.zeros((C,d,d))
for i in range(C):
diff = (X-mu[i])
weighted_sum = np.dot((gamma[:,i].reshape(-1,1)*diff).T,diff)
sigma[i,:,:] = weighted_sum/resp_weights[i]
return pi, mu, sigma
def train_EM(X, C, rtol=1e-3, max_iter=100, restarts=10):
'''
Starts with random initialization *restarts* times
Runs optimization until saturation with *rtol* reached
or *max_iter* iterations were made.
X: (N, d), data points
C: int, number of clusters
'''
N = X.shape[0] # number of objects
d = X.shape[1] # dimension of each object
best_loss = -np.inf
best_pi = None
best_mu = None
best_sigma = None
for _ in range(restarts):
try:
pi = np.ones(C)/float(C)
mu = np.random.randn(C,d)
sigma = np.zeros((C,d,d))
sigma[...] = np.identity(d)
prev_loss = None
for _ in range(max_iter):
gamma = E_step(X,pi,mu,sigma)
pi,mu,sigma = M_step(X,gamma)
loss = compute_vlb(X,pi,mu,sigma,gamma)
if not np.isnan(loss) and loss>best_loss:
best_loss = loss
best_mu = mu
best_pi = pi
best_sigma = sigma
if prev_loss is not None:
diff = np.abs(prev_loss-loss)/np.abs(prev_loss)
if diff < rtol:
break
prev_loss = loss
except np.linalg.LinAlgError:
print("Singular matrix: components collapsed")
pass
return best_loss, best_pi, best_mu, best_sigma
Benefits of GMM models: in unsupervised clustering for example, KNN methods accuracy will increase as we increase the number of groups. So you never know how many groups are better for KNN methods. In GNN on the other hand, the accuracy increases and then decreases. So increasing the number of clusters does not necessary increase the accuracy.
Dirichlet Distribution
A Dirichlet distribution is defined as
\[f(\theta;\alpha) = \frac{1}{B(\alpha)} \Pi_{i=1}^K \theta_i^{\alpha_i-1}\]Note that \(\sum_{i=1}^K \theta_i = 1\) and \(\theta_i>0\). The expected value and variance can be found as
Note that the Dirichlet distribution is conjugate to the multinomial distribution as
\[p(\theta) = \frac{n!}{x_1! \cdots x_K!} \Pi_{i=1}^K \theta_i^{x_i}\]So if prior has a Dirichlet distribution, and likelihood is a multinomial, then the posetrior will also be a Dirichlet distribution.
Latent Dirichelet Model
Imagine the following model for the distribution of words in a document
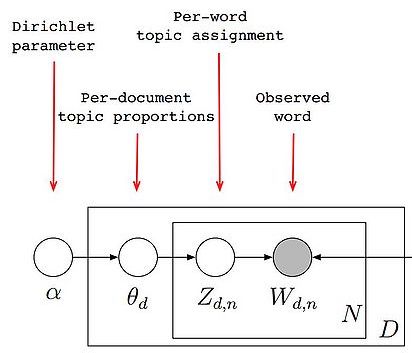
In latent Dirichelet model, we have
\[p(W,Z,\theta) = \Pi_{d=1}^D p(\theta_d) \Pi_{n=1}^{N_d} p(z_{dn}\mid \theta_d)~p(w_{dn}\mid z_{dn})\]where \(p(\theta_d)\sim \text{Dir}(\alpha)\), and \(p(z_{dn}\mid \theta_d) = \theta_{dz_{dn}}\), and \(p(w_{dn}\mid z_{dn}) = \Phi_{z_{dn},w_{dn}}\), where \(\sum \Phi_{z_{dn},w_{dn}} =1\). In order to calculate the E-step, we first need to find the log-likelihood, where we have
\[\log p(W,Z,\theta) = \sum_{d=1}^D \left[ \sum_{t=1}^T (\alpha_t-1) \log \theta_{dt} + \sum_{n=1}^{N_d} \sum_{t=1}^T \mathbf{1}(z_{dn}=t) \left(\log \theta_{dt} + \log \phi_{tw_{dn}} \right) \right] + \text{C.}\]In the E-step, we want to
\[\min D_{KL}\left( q(\theta) q(Z) \\mid p(\theta,Z\mid W) \right)\] \[\log q(\theta) = \mathbf{E}_{q(z)} \log p(\theta,Z,W) = \mathbf{E}_{q(z)} \log p(\theta,Z\mid W) + C.\] \[\begin{align*} \log q(\theta) &= \mathbf{E}_{q(z)} \sum_{d=1}^D \left[ \sum_{t=1}^T (\alpha_t-1) \log \theta_{dt} + \sum_{n=1}^{N_d} \sum_{t=1}^T \mathbf{1}(z_{dn}=t) \left(\log \theta_{dt} + \log \phi_{tw_{dn}} \right) \right] \\ &= \mathbf{E}_{q(z)} \sum_{d=1}^D \left[ \sum_{t=1}^T (\alpha_t-1) \log \theta_{dt} + \sum_{n=1}^{N_d}\sum_{t=1}^T \mathbf{1}(z_{dn}=t) \left(\log \theta_{dt} \right) \right] \\ &= \sum_{d=1}^D \left[ \sum_{t=1}^T (\alpha_t-1) \log \theta_{dt} + \sum_{n=1}^{N_d} \sum_{t=1}^T \mathbf{E}_{q(z)}\left[\mathbf{1}(z_{dn}=t)\right] \left(\log \theta_{dt} \right) \right] \\ &= \sum_{d=1}^D \sum_{t=1}^T \log \theta_{dt} \left[ (\alpha_t-1) + \sum_{n=1}^{N_d} \mathbf{E}_{q(z)}\left[\mathbf{1}(z_{dn}=t)\right] \right] \end{align*}\]So in summary, we have
\[\boxed{\log q(\theta) = \sum_{d=1}^D \sum_{t=1}^T \log \theta_{dt} \left[ (\alpha_t-1) + \sum_{n=1}^{N_d} \gamma_{dn}^t \right]} \\ \boxed{\gamma_{dn}^t = \mathbf{E}_{q(z)}\left[\mathbf{1}(z_{dn}=t)\right]}\] \[\to q(\theta) \propto \Pi_d \Pi_t \theta_{dt}^{\left[\alpha_t + \sum_n \gamma^t_{dn} - 1\right]}\]Now, let’s take the E-step for \(q(Z)\), we have
\[\begin{align*} \log q(Z) &= \mathbf{E}_{q(\theta)} \sum_{d=1}^D \left[ \sum_{t=1}^T (\alpha_t-1) \log \theta_{dt} + \sum_{n=1}^{N_d} \sum_{t=1}^T \mathbf{1}(z_{dn}=t) \left(\log \theta_{dt} + \log \phi_{tw_{dn}} \right) \right] \\ &= \mathbf{E}_{q(\theta)} \sum_{d=1}^D \sum_{n=1}^{N_d} \mathbf{1}(z_{dn}=t) \left(\log \theta_{dt} + \log \phi_{tw_{dn}} \right) \\ &= \sum_{d=1}^D \sum_{n=1}^{N_d} \mathbf{1}(z_{dn}=t) \left(\mathbf{E}_{q(\theta)} \log \theta_{dt} + \log \phi_{tw_{dn}} \right) \end{align*}\]so in summary
\[\boxed{\log q(Z) = \sum_{d=1}^D \sum_{n=1}^{N_d} \mathbf{1}(z_{dn}=t) \left(\mathbf{E}_{q(\theta)} \log \theta_{dt} + \log \phi_{tw_{dn}} \right) }\] \[\to q(Z) = \Pi_d \Pi_t q(z_{dn})\\ q\left( z_{dn}=t\right) = \frac{\phi_{t w_{dn}} \exp \left( \mathbf{E}_{q(\theta)} \log \theta_{dt} \right)}{\sum_{t'} {\phi_{t' w_{dn}} \exp \left( \mathbf{E}_{q(\theta)} \log \theta_{dt'} \right)}}\]and in the M-step we would like to maximize the following
\[\begin{align*} \mathbf{E}_{q(\theta)q(Z)} \log p(\theta,Z,W) &= \mathbf{E}_{q(\theta)q(Z)} \left[ \sum_{d=1}^D \left[ \sum_{t=1}^T (\alpha_t-1) \log \theta_{dt} + \sum_{n=1}^{N_d} \sum_{t=1}^T \mathbf{1}(z_{dn}=t) \left(\log \theta_{dt} + \log \phi_{tw_{dn}} \right) \right] \right] \\ &= \mathbf{E}_{q(\theta)q(Z)} \left[ \sum_{d=1}^D \sum_{t=1}^T \sum_{n=1}^{N_d} \mathbf{1}(z_{dn}=t) \log \phi_{tw_{dn}} \right] \\ &= \sum_{d=1}^D \sum_{t=1}^T \sum_{n=1}^{N_d} \mathbf{E}_{q(\theta)q(Z)} \left[\mathbf{1}(z_{dn}=t)\right] \log \phi_{tw_{dn}} \\ &= \sum_{d=1}^D \sum_{t=1}^T \sum_{n=1}^{N_d} \gamma_{dn}^t \log \phi_{tw_{dn}} \end{align*}\]given that \(\sum_w \phi_{tw} = 1\) and also \(\phi_{tw}\geq 0\). We use lagrangian to maximize the above equation, we have
\[L = \sum_{d=1}^D \sum_{t=1}^T \sum_{n=1}^{N_d} \gamma_{dn}^t \log \phi_{tw_{dn}} - \sum_{t=1}^T \lambda_t \left(\sum_w \phi_{tw}-1\right)\]Now we take the derivative to maximize the above equation, we find
\[\frac{\partial L}{\partial \phi_{tw}} = \sum_{d=1}^D \sum_{n=1}^{N_d} \gamma_{dn}^t \frac{1}{\phi_{tw}}\mathbf{1}\left[w_{dn} = w\right] - \lambda_t = 0 \\ \phi_{tw} = \frac{\sum_{d=1}^D \sum_{n=1}^{N_d} \gamma_{dn}^t \mathbf{1}\left[w_{dn}= w\right]}{ \lambda_t}\]Knowing that \(\sum_w \phi_{tw} = 1\), we can find that
\[\phi_{tw} = \frac{\sum_{d=1}^D \sum_{n=1}^{N_d} \gamma_{dn}^t \mathbf{1}\left[w_{dn}= w\right]}{ \sum_w \sum_{d=1}^D \sum_{n=1}^{N_d} \gamma_{dn}^t \mathbf{1}\left[w_{dn}= w\right]} \\ \to \boxed{\phi_{tw} = \frac{\sum_{d,n} \gamma_{dn}^t \mathbf{1}\left[w_{dn}= w\right]}{ \sum_{d,n,w'} \gamma_{dn}^t \mathbf{1}\left[w_{dn}= w'\right]}}\]Monte-Carlo Method
Estimating expected values using sampling
\[\mathbf{E}_{p(x)} f(x) = \frac{1}{M} \sum f(x_s), \quad \text{where } x_s\sim p(x)\]Now the question is how to sample from a probability distribution \(p(x)\)? In the following we will discuss this. Note that we assume that generating a random number with uniform distribution from in \([0,1]\) is given, i.e., we can easily sample form \(\mathcal{U}(0,1)\).
Sampling from 1-D distribution
Consider a distribution over discrete set such as \(p(a_i) = p_i\) for \(i=1,\cdots,n\). Note that \(\sum_i p_i = 1\). We can separate the \([0,1]\) distance proportional to the \(p_i\). Next, we sample a point from $[0,1]$ using the uniform distribution, we can assign it to the discrete values of \(a_i\) based on the interval that it lands into. Here is an example:
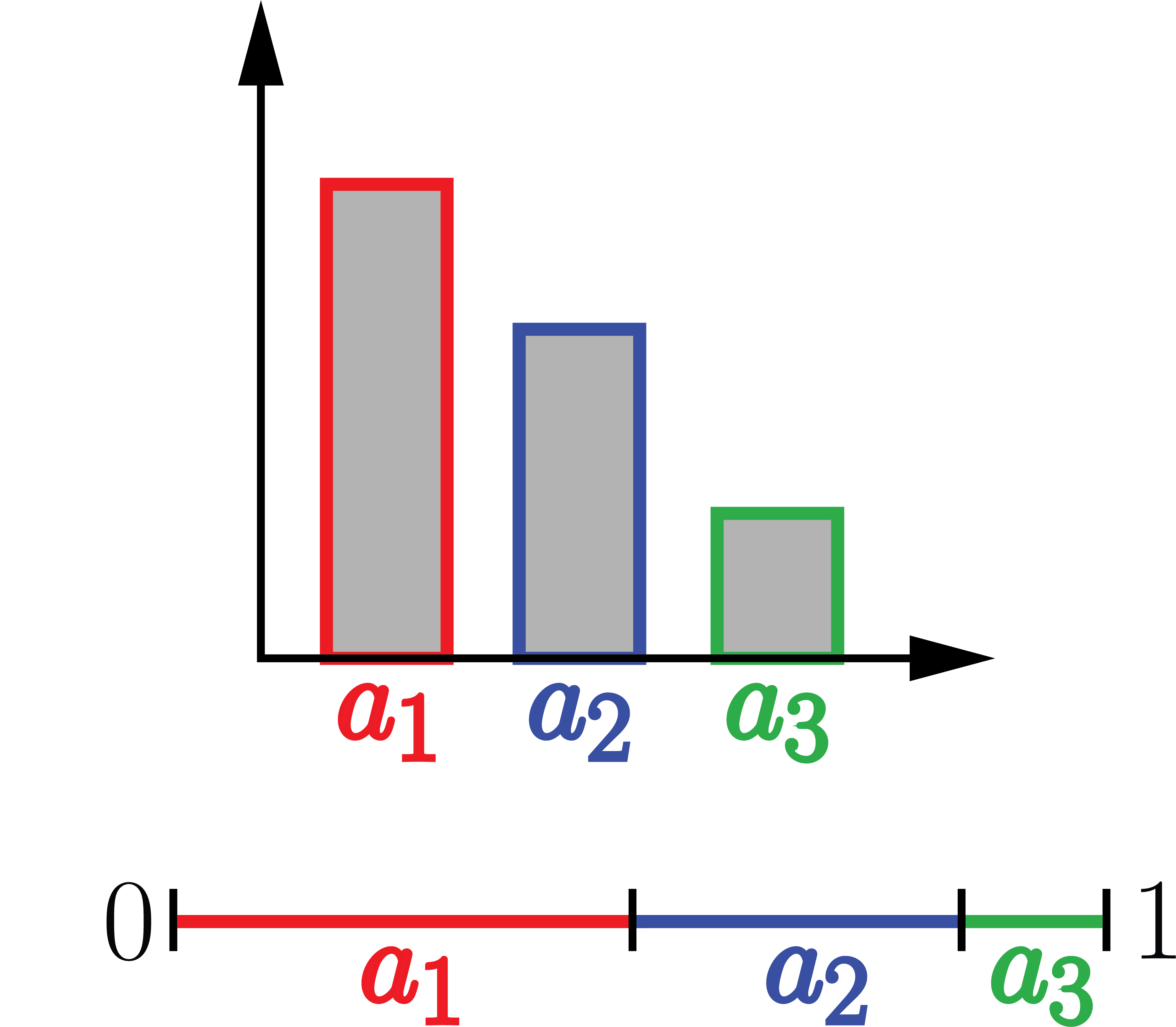
Sampling Normal distribution:
We can generate normal distribution using central limit theorem, i.e.
\[x = \frac{1}{\sqrt{N}} \left[ \sum_{i=1}^N \left( x_i - \frac{1}{2}\right) \right]\]As the \(N\to \infty\), the \(p(x) \to \mathcal{N}(0,1)\). This has been done very efficiently, and we can use packages such as np.random.randn() to generate these numbers. Now imagine that we are interested in 1d sampling from a continuous distribution such as \(p(x)\) shown below
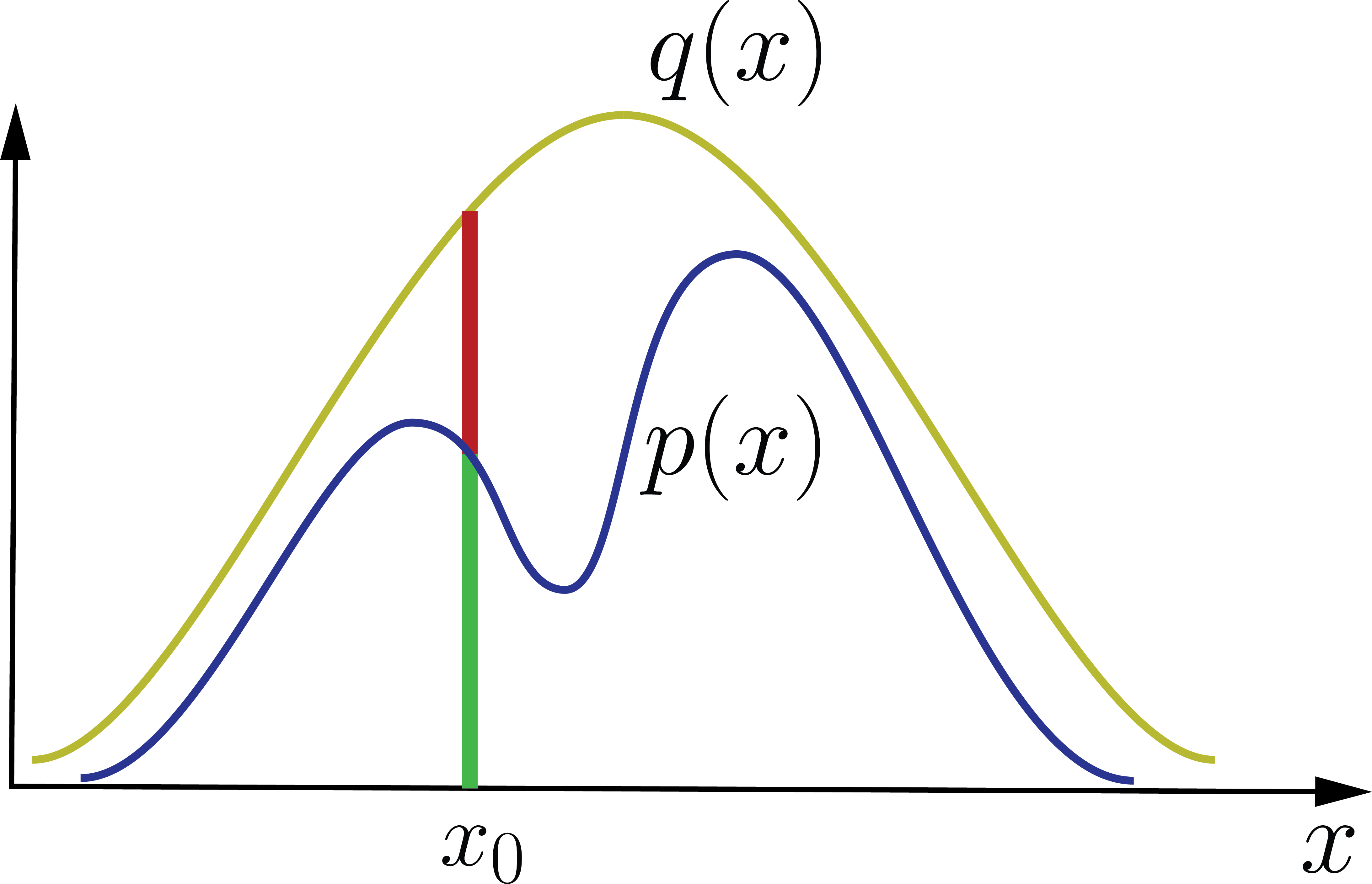
One way to sample from \(p(x)\) in the above is to first bound the pdf by some normal distribution $q(x)$. Next, we generate a random point, say \(x_0\). We then accept this point with probability \(\alpha= p(x)/q(x)\) and reject it with \(1-\alpha\). This way, we create samples from the \(p(x)\).
Markov-Chains
There are two methods that we will introduce here (Metropolis-Hasting and Gibbs sampling) that depend on Markov-Chain. A few introductory remarks on Markov-process is helpful before we talk about them.
Let \(X_t\) denote the value of a random variable at time $t$. The state space is the space of all possible values for $X$ values. The random variable is called a Markov process if the transition probabilities betwen different values in the state space only depend on the current’s value of the random variable, i.e.,
\[p(X_{t+1}=s_{j}\mid X_0=s_k, \cdots, X_t=s_i) = p(X_{t+1}=s_{j}\mid X_t=s_i)\]A Markov-Chain referes to a sequence of random variables \((X_0, \cdots,X_n)\) generated by a markov process. Transition probability (or the transition kernel) gives us the probability of transitioning between the states ina single step, i.e.,
\[p(i\to j) = p(X_{t+1}=s_j\mid X_{t}=s_i)\]Using the transition kernel, if we are at state \(s_i\) we can define a row vector for the state space probabilities, i.e., \(\pi_i(t) = p(X_t = s_i)\). The evolution of this state space probabilities can be obtained using the kernel as
\[\pi_j(t+1) = p(X_{t+1}=s_j) \\= \sum_k p(X_{t+1}=s_j\mid X_t = s_k) p(X_t = s_k) = \sum_k p(k,j) \pi_k(t) \\ \mathbf{\pi}(t+1) = \mathbf{\pi}(t) \mathbf{P}\]As a result, we can find that \(\pi(t) = \pi(0) \mathbf{P}^k\). A distribution of states $\mathbf{\pi}^*$ is called stationary if \(\mathbf{\pi}^* = \mathbf{\pi}^*\mathbf{P}\). A sufficient condition for a unique stationary distribution is that the detailed balance condition holds
\[p(j\to k) \pi^*_j = p(k\to j) \pi^*_k\]If the above condition holds then we have
\[(\mathbf{\pi}\mathbf{P})_j = \sum_i \pi_i P(i,j) = \sum_i \pi_i P(i\to j) \\= \sum_i \pi_j P(j\to i) = \pi_j \sum_i P(j\to i) = \pi_j\]Metropolis-Hasting Algorithm
So our goal is to generate a sample with PDF \(p(x)\). In Metropolis-Hasting the basic idea is to create a Markov-Process to generate new data points where \(p(x)\) is its stationary distribution. If \(p(x)\) is stationary distribution, then using following the Markov process for a long time we will generate data-points that have the distribution of \(p(x)\). But how can we create a Markov-Process where \(p(x)\) is its stationary distribution? We can use the idea of rejecting points. We start with any Markov-process \(Q\) (as long as we have a non-zero probability of going over all the data points), we then start from a data-point \(x_0\) (or state) and find our new data-point \(x_1\) (the new state). Now we have an option of accepting this new state or rejecting it. We select this acceptance/rejection probability such that our \(p(x)\) becomes the stationary distribution of our Markov process.
\[p(x_0) Q(x_0\to x_1) A(x_0 \to x_1) = p(x_1) Q(x_1\to x_0) A(x_1 \to x_0) \\ \frac{A(x_0 \to x_1)}{A(x_1 \to x_0)} = \frac{p(x_1)}{p(x_0)} \frac{Q(x_1\to x_0)}{Q(x_0\to x_1)} = \rho\]So as long as our acceptance probability follows the above equality, we are doing well. Assume that the above proportionality is \(\rho\). If \(\rho\leq 1\), we can have \(A(x_0\to x_1) = \rho, A(x_1\to x_0) = 1\). On the other hand, if \(\rho>1\), we can assign \(A(x_0\to x_1) = 1, A(x_1\to x_0) = 1/\rho\). So basically, we can assign the following acceptance probability
\[A(x_0\to x_1) = \begin{cases} \rho & \rho \leq 1 \\ 1 & \rho >1 \end{cases}\]Or we can summarize it as
\[A(x_0\to x_1) = \min\left(1, \frac{p(x_1)}{p(x_0)} \frac{Q(x_1\to x_0)}{Q(x_0\to x_1)} \right)\]